









前言
在本文中,我們不急著寫程式,先介紹 Selenium 和網路爬蟲的概念。本文短短的內容無法讓讀者變成網路爬蟲的專家,但可知道如何開始,以繼續學習。
網路爬蟲的用途
網路爬蟲的用途在於自動化瀏覽網站、操作網頁及抓取資料的過程。像是 Google 或 Bing 等搜尋引擎,每日要爬取大量的網站,以建立搜尋引擎所需的索引,由於網站多、資料量大,手動操作變得不切實際,這時候就會用爬蟲做為自動化抓取網頁資料的一部分。即使對於一般使用者來說,網路爬蟲可重覆操作的特性,搭配類 Unix 系統的 cron 或其他系統排程軟體就可以省下許多單調、機械性的手工。
Selenium 的學習地圖
網頁主要由 HTML、CSS、JavaScript 等前端技術所組成,基本上就是瀏覽網頁原始碼時會看到的東西。如果想要學習網頁爬蟲,不用精通這三者,但至少要能閱讀大部分的 HTML 標籤和 CSS selectors。
由於直接閱讀網頁原始碼較困難,而且有些由 JavaScript 動態生成的頁面無法直接靠閱讀網頁原始碼取得;使用瀏覽器內附的開發者工具,可用來輔助我們閱讀網頁原始碼,因為可以透過開發者工具的視覺提示,得知目前的標籤位於網頁上的什麼位置;而且頁面改變時,開發者工具內的程式碼也會跟著改變。
對於爬蟲新手來說,一開始通常從 requests 這類 HTTP clients 開始學,但使用 Selenium 反而是最簡單的。因為 HTTP clients 「上網」的行為和瀏覽器有一些差異,得額外用一些手法模擬,才會「像」一般使用者。相對來說,Selenium 透過操作瀏覽器來存取網頁,「看起來」比較像一般使用者。
有些網站會透過網頁的 header 確認目前瀏覽網頁的使用者 (user) 是人 (human) 還是機器人 (bot),一般的爬蟲沒有瀏覽器特有的 header,要自行加入,但 Selenium 是透過瀏覽器來存取網頁,沒有 header 的問題。另外,有些網站會透過 cookie 等客戶端資料 (client data) 來確認使用者的狀態,這在一般的 HTTP clients 也要另外處理,但 Selenium 程式是直接使用現有的瀏覽器,這些問題可自動處理。
何時使用 Selenium?
理論上 Selenium 適用於所有的情境,但有時候效率不一定是最好的,對於多頁面且網址變動規律的靜態頁面,使用 requests 等 HTTP clients 搭配 BeautifulSoup 這類 HTML 解析器 (parsers) 會比使用 Selenium 快得多。相對來說,表單 (forms) 或是由 JavaScript 動態生成的頁面,以 requests 等傳統的 HTTP clients 相對不易處理,這時候就可以考慮使用 Selenium。
如果碰到網頁改版時,原有的爬蟲可能會失效,這時候就要重新撰寫爬蟲。雖然爬蟲的理想是全自動化處理,但有時仍要手動修改程式。如果不想自己撰寫爬蟲,但又時常有這方面的需求,也可透過外包網站找尋長期合作的工程師。一般來說,一個不要太複雜的爬蟲應可在數天內完成。
建立 Selenium 開發環境
本系列文章大部分使用 Python。透過以下指令可安裝適用於 Python 的 Selenium 套件:
$ pip install selenium另外還要針對使用的瀏覽器安裝相對應的 web driver,我們會使用 Chrome,這部分請讀者自行完成。
撰寫 Selenium 的流程
Selenium 程式的執行流程大抵如下:
- 設置偏好,像是下載位置等
- 選定 web driver
- 前往目標網頁
- 操作網頁
- 從連結下載資料或從頁面本身取得資料
大部分核心的工作會落在 (4),少數會在 (5)。一開始寫爬蟲碰到困難通常不是 Python 語法的問題,而是不知道怎麼有效率地觀察網頁。筆者目前偏好用 Chrome 的開發者工具協助觀察頁面,如下圖:
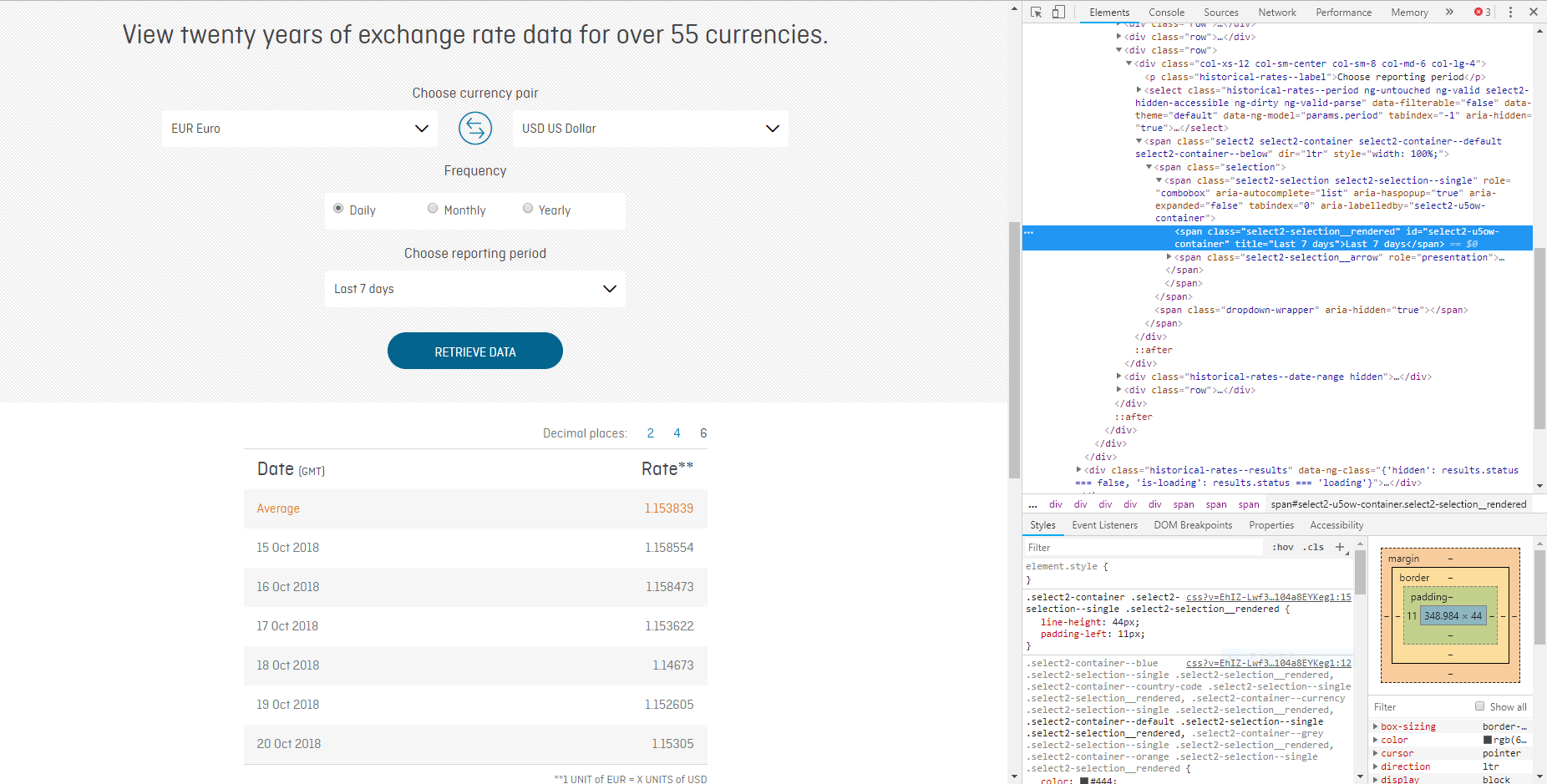
新版的 Chrome 或其他瀏覽器可在網頁元件上按右鍵選「檢查」,就可以直接觀察頁面對應的網頁元素。要如何定錨網頁元素呢?這個只能見招拆招,還要請讀者多練習幾次,原則就是用較具獨特性的 class、id、屬性 (attribute) 將網頁元素的範圍逐一縮小到單一的元素即可。